We all know that every machine learning model should come up with high accuracy (without overfitting). That means the model should predict the correct output on the testing data or unseen data. The main target of all machine learning model is to predict the correct output on the testing data.
Hypothesis (h):
A hypothesis is a function, by using that the model can predict the target value or output. It is simply a function with some coefficients and variables. The variables are the attributes of the dataset. By providing the values of the attribute the model can come up with the predicted output value.
Hypothesis Space (H):
Hypothesis space is a collection of all possible hypothesis which can predict the output. It is a set of all hypothesis from which machine learning model choose the best one which can best describe the output values.
Let's understand with an example:
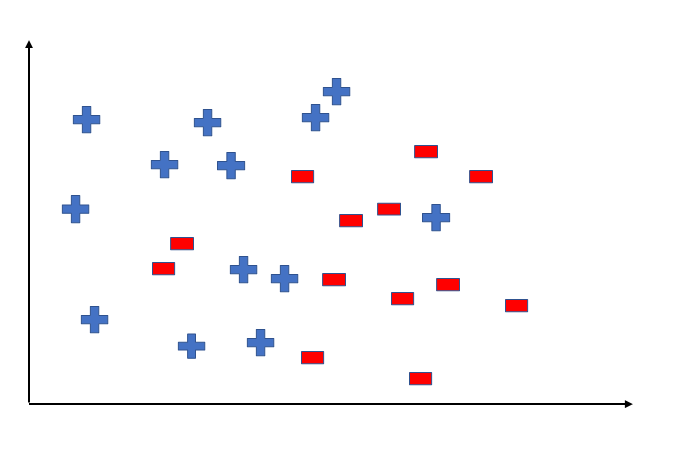
Let's say, we have a dataset with some attributes and some rows. We will plot all values in the graph and the graph will look as follows.
Now, we have some data points but don't know it's class, whether it belongs to + or -. To predict the class of that new data point, we will come up with a hypothesis function. By using that hypothesis function we can predict its class.
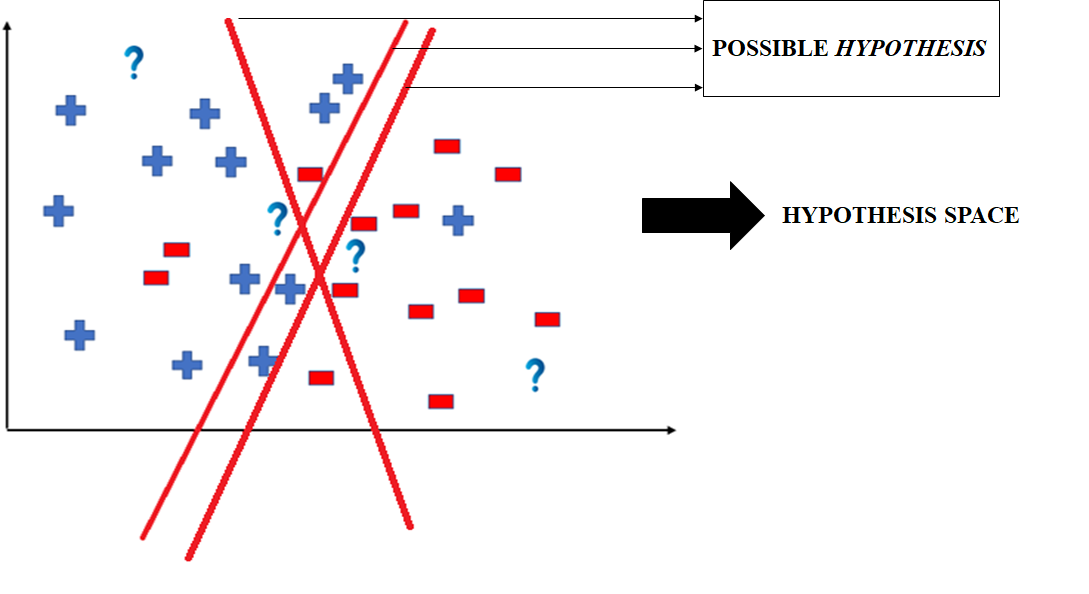
But we can notice that we can also divide the data point class with some different hypotheses. We can come up with more than one hypothesis, and the collection of all hypothesis is a hypothesis space. The following image shows the hypothesis space. The machine learning model will choose the best (only one) hypothesis from the hypothesis space for the prediction.
Now, we have understood the hypothesis space. Let's go to inductive bias.
Inductive Bias:
Inductive bias is a set of assumptions made while training and implementing the model of machine learning. So that it can predict the output with more accuracy. It is also called learning bias. The main goal of the machine learning model is to learn to predict the output. But for that, we have to make some assumptions. For example, every linear supervised learning algorithm assumes that all input points are linearly related to the output data points. We know it is not true for all data points in the dataset, but still, we have to make this assumption in linear supervised learning to predict the output.
Conclusion:
- A hypothesis is a function by using it, the machine learning model can predict the output.
- A collection of all possible legal hypothesis is called hypothesis space. The machine learning model chooses any one hypothesis which is best to predict the output.
- Inductive bias/learning bias is a set of assumptions made by the user to train the model and come up with the predicted output.
Thank you
Comments
Post a Comment